Warning: Undefined array key 0 in /home/xs372180/pnpk.net/public_html/wp-content/plugins/multi-page-toolkit/TA_multi_toolkit.php on line 151
Warning: Undefined array key 2 in /home/xs372180/pnpk.net/public_html/wp-content/plugins/multi-page-toolkit/TA_multi_toolkit.php on line 152
Warning: Undefined array key 0 in /home/xs372180/pnpk.net/public_html/wp-content/plugins/multi-page-toolkit/TA_multi_toolkit.php on line 202
Warning: Undefined array key 1 in /home/xs372180/pnpk.net/public_html/wp-content/plugins/multi-page-toolkit/TA_multi_toolkit.php on line 202
Warning: Undefined array key 0 in /home/xs372180/pnpk.net/public_html/wp-content/plugins/multi-page-toolkit/TA_multi_toolkit.php on line 151
Warning: Undefined array key 2 in /home/xs372180/pnpk.net/public_html/wp-content/plugins/multi-page-toolkit/TA_multi_toolkit.php on line 152
Warning: Undefined variable $more in /home/xs372180/pnpk.net/public_html/wp-content/plugins/multi-page-toolkit/TA_multi_toolkit.php on line 233
Warning: Undefined variable $allpage_link in /home/xs372180/pnpk.net/public_html/wp-content/plugins/multi-page-toolkit/TA_multi_toolkit.php on line 233
Warning: Undefined variable $allpage_link in /home/xs372180/pnpk.net/public_html/wp-content/plugins/multi-page-toolkit/TA_multi_toolkit.php on line 241
Warning: Undefined variable $allpage_link in /home/xs372180/pnpk.net/public_html/wp-content/plugins/multi-page-toolkit/TA_multi_toolkit.php on line 244
ページ : 1 2
<この記事を全て表示する場合はこちらをクリック>
XML生成用ファイルの設置
検索サーバの、以下のディレクトリにフォルダ”SEARCH”を作成します。
さらにその中に”Google.aspx”と”Google.aspx.cs”を保存し、”Google.aspx.cs”の中身を以下の文字列で上書きします。
※Googleの検索結果が変更になった場合、動作しなくなる可能性がありますのでご注意を。
2009年2月7日追記
searchPatternを以下に変更すると早くなった気がするんだけど・・・どうでしょうか。
でも根本的にどこが原因なのか分かってません。
Search Server 2008の検索結果にキャッシュとかの表示は必要ないのかなと思い、その部分を削ってみました。
動作確認

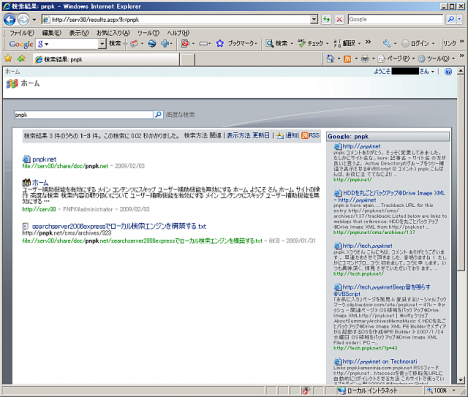
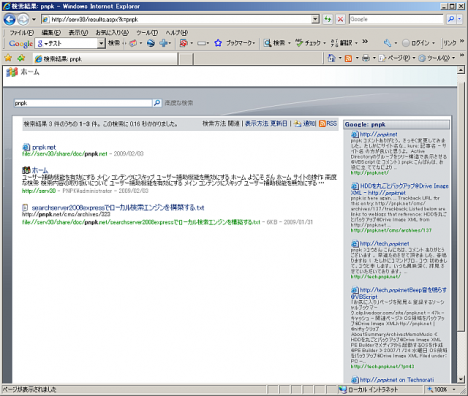
以下のサイトにアクセスし、検索結果が正常に出力されているか確認します。
正常に出力されていれば、これで設定完了です。
Search Server 2008へパーツとして組み込み

サイトの操作権限のあるアカウントで検索結果画面にアクセスし、”ページの編集”を選択します。

“WEBパーツの追加”を選択し、”フェデレーション検索結果”にチェックを入れ、”追加”を選択します。

“共有WEBパーツの変更”を選択します。

“場所”の選択で”Google”を選択し、”OK”を選択します。

“編集モードの終了”を選択し、完了です。
既知の問題点
英数字を検索すると結果が返ってくるのが早いのですが、2バイト文字を検索するとたまに激しく重い上にCPUリソースの使いっぷりが凄まじくなります。
例えば”フェデレーション”で検索するととても高速ですが、”自転車”と検索すると反応が返ってくるまでに30秒くらいかかってしまいます。
こちら何かご存じの方いらっしゃれば是非教えてください。
遅い件、解決しました。
参考リンク
Search Server 2008: Federated sites that do not return XML
http://www.21apps.com/sharepoint/search-server-2008-federated-sites-that-do-not-return-xml/
ページ : 1 2
<この記事を全て表示する場合はこちらをクリック>